
Have you ever watched the Science channel show called, Engineering Catastrophes? It’s a fascinating show exemplifying how engineering projects of all sizes can be brought down due to a single (and sometimes, tiny) engineering design flaw. There are plenty of reasons for the disaster—failure to account for environmental factors, rushed or missed work, misjudgments, lack of regulatory or safety compliance, and so on. But the most common factor: a crucial flaw in the initial design and/or changes made to that design during construction. They say, when building big, every component, no matter how small, is crucial. Could we not say the same about the industrial data value chain?
On a recent customer call, a prospect shared with us that, they “are not at a place right now to be prioritizing the quality of the data over the exercise of aggregation and streamlining the data collection.” This exemplifies a strange cognitive dissonance, where some companies say, “Yes, we do need to aggregate and store the data, but we’re not concerned with its quality.” That is, “We need the data, but we don’t need it to be usable.” What??? Isn’t the crucial (and rather large) detail to using data, its accuracy and reliability?
This has all the makings of a Data Catastrophe: ignoring the crucial factor that impacts every application based on that data. To avoid such a catastrophe, you will need a comprehensive Data Strategy. But half of technology leaders in a Pulse by Gartner poll said that the lack of a clearly articulated data strategy is the #1 challenge inhibiting the progress of data-driven projects; more than technology, ROI, funding, or talent.
Why is creating a thorough and successful data strategy so difficult? The sheer size of the data problem often forces strategists to narrow the scope to meet the highest priorities and are frequently reactive in nature. Competing projects or functions, such as, data visualization and analytics, where it’s easier to prove impact and ROI, often rise to the top. It’s a can’t see the forest for the trees situation. A data strategy is not a series of IT projects or tools that fit a certain function. Rather, it starts with understanding the industrial data value chain (at right) and how interdependent these data functions are to each other.
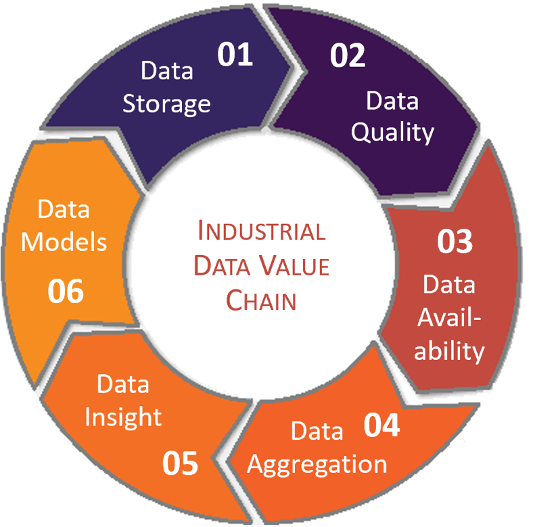
In which functions have you made investments? I’d venture to say some, but not all. In another Pulse by Gartner poll, two-thirds said data quality is causing the most pain for their company. So, why do we focus so much on security, aggregation, and/or analytics? Data Quality is intrinsic to a successful data strategy, as the infrastructure layer between the historian and the uses of data. It can be the crucial design flaw to your entire strategy if it’s not done properly or ignored for higher, more visibly-calculable ROI applications of other data functions.
Data quality issues should be treated with the same severity as an engineering failure to a road, bridge, or building. Some notable plant incidents show how data quality failures severely impact performance. For example:
- The 2005 Texas City explosion at BP was caused by the failure of a single sensor (and a series of unwisely-made gut decisions) that told operators the isomerization column was not filling. They continued to pump in hydrocarbons leading to over-pressurization and then a spark caused the deadly explosion. [Engineering Catastrophes S5, EP3]
- In the last 11 minutes before the Milford Haven refinery explosion, two operators had to recognize and act upon 275 alarms. Another 1765 alarms were displayed as high priority, despite many of them being informative only.
- In 2019, a Top 20 Chemicals company lost €160M from unplanned outages and lost production. 80% of this lost was attributed to the accurate detection of sensor data issues. Operators found it difficult to trust the data, instead relying on experience.
- As nations drive towards a future of net zero, cities and companies must accurately report their greenhouse gas emissions to regulatory agencies. In 2020, GHG emissions were under-reported by an average 23.5%, leading to significant fines.
In these examples, an established, well-defined data strategy, where data quality is guaranteed, would have eliminated these “failures.” Operators require reliable, accurate data upon which to make data-driven decisions. Data scientists need to focus on higher-value functions like data aggregation, insight, and analytics, instead of cleaning data. Executives need accurate data upon which to base their business decisions. It begins with Data Integrity and it’s more than just quality.
