
Migrating data to the public cloud offers a wide range of benefits for enterprises; data teams can more easily access their data, write, and test data science models, evaluate new data platforms and test applications, run POCs, and deploy in production. But with the advantages cloud migration and cloud platforms offer, enterprises must understand that as soon as they introduce data into the cloud, they become responsible for ensuring compliance with stringent regulations like GDPR, CCPA, LGPD, PPO, SOC, and HIPAA.
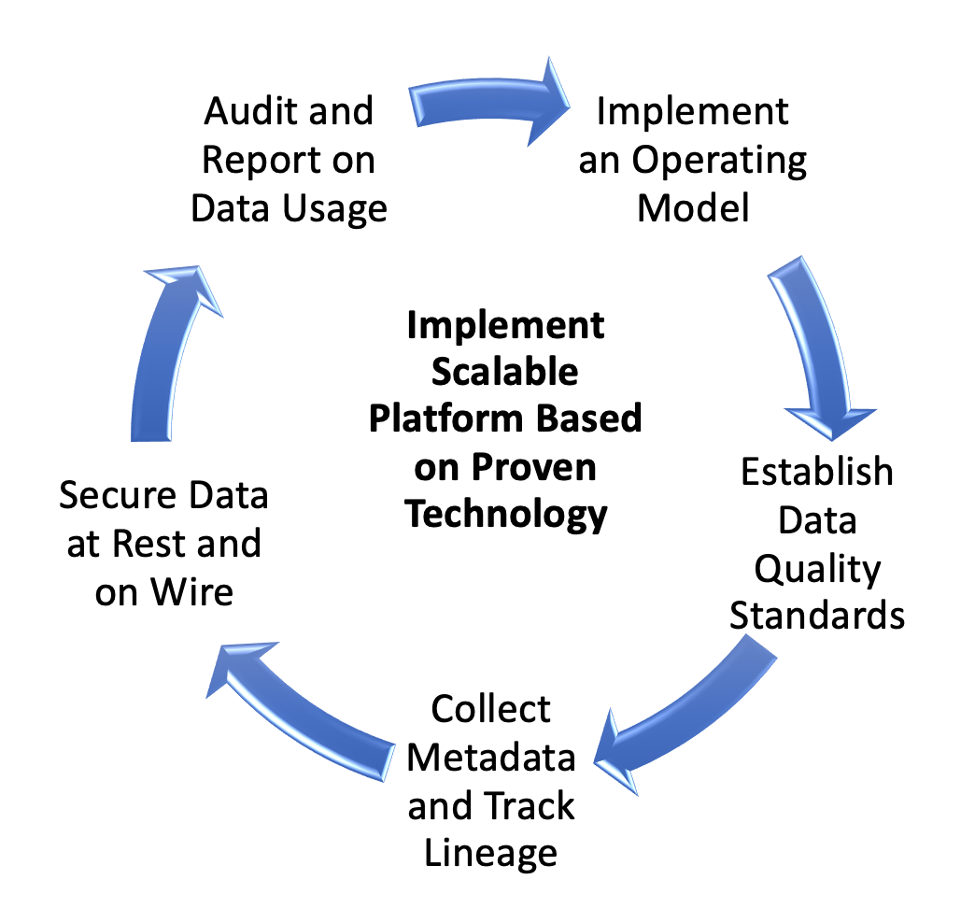
The most important question we hear from enterprises planning their data migration is: “How are we going to secure and govern data in the cloud?” From an operating model perspective, the ownership and stewardship of data remain the same. Data quality can also be implemented similarly to an on-premise environment. However, ensuring data security, collecting metadata and audits, tracking lineage, and evaluating multiple technologies pose new challenges for data teams that must be considered before cloud migration takes place.

Data Security in the Cloud
Before data can be migrated to the cloud, enterprises must first determine how to enable analytics, while ensuring data security, which includes: encrypting sensitive data, implementing fine-grained data access controls, and auditing all access to data to report suspicious activity.
Data in the cloud, for the most part, resides in a cloud data lake running on an object store (e.g., S3, ADLS, GCS). All of these cloud data stores support few basic security requirements:
- Transparent data encryption at rest (protects against unauthorized access to the physical storage media)
- Coarse-grained data access control via IAM roles (difficult to scale due to complexity)
However, there are several additional security requirements enterprises must consider to ensure that once the data is migrated, it is secure, useable for analysis, and compliant with regulations:
- A catalog of all sensitive data
- Data access controls
- Data masking and anonymization capabilities
- Encryption of sensitive data at the attribute/field level
Metadata and Lineage in the Cloud
Because data in the cloud is replicated by data scientists and analysts for experiments and new products, enterprises must ensure data usage is tracked, tagged, and handled in a secure manner without violating compliance requirements. Collecting and sharing metadata ensures data is easier to find–which reduces replication, enables easier governance, and simplifies auditing and reporting. Most importantly, metadata collection and lineage tracing ensure all data is tracked, so it can be reliably deleted when requested by customers under GDPR, CCPA, and other industry or privacy regulations. Privacera integrates with all leading metadata and lineage technologies–such as Collibra, Informatica, Alation, and more–to exchange sensitive metadata in order to implement policies to ensure compliance with data regulations.
Data Access Control in the Cloud
Cloud platforms provide a coarse-grained access control mechanism via Identity Access Management (IAM) roles; however, IAM is complex, difficult to scale, and lacks fine-grained access control to sufficiently meet security requirements. There are numerous data processing engines used to access data in the cloud data lake (e.g., Databricks, Snowflake, Presto, Redshift, Synapse, as well as in-house custom applications used for data analytics and processing). Some of these platforms provide needed security controls, like column-level access control, data masking, and row-level filters. However, these features are not supported consistently across all of these platforms. Additionally, these security controls must be managed in each platform separately, which requires more resources and increases the risk of human error. That in turn can lead to unauthorized access to data. To ensure consistent data access management across all cloud platforms, enterprises require a data access management platform that simplifies data access control and provides a single-pane view of all data access policies in the cloud.
Data Governance Technology in the Cloud
As data migrates to the cloud, enterprises must consider cloud-native technologies to support their governance efforts. While some on-prem technologies have a corresponding cloud version, many do not provide equivalent support or do not address new security and governance challenges in the cloud. If your enterprise is considering cloud migration or has already migrated data to the cloud and discovered governance challenges, modern cloud-native technologies should be evaluated to ensure end-to-end governance (metadata management, lineage, access control, data dictionaries and catalogs, auditing, and reports).
