Building a Predictive Model using Python Framework: A Step-by-Step Guide

Challenging the status quo can be dangerous. Facts are sacred, and the future is inevitable. Any method of predicting the future requires scrutinizing many details.
Even though the organization leaders are familiar with the importance of analytics for their business, no more than 29% of these leaders depend on data analysis to make decisions. More than half of these leaders confess a lack of awareness about implementing predictions.
Predictive analytics is a new wave of data mining techniques and technologies which use historical data to predict future trends. Predictive Analytics allows businesses and investors to adjust their resources to take advantage of possible events and address issues before becoming problems. It can determine customer behavior based on what they’ve done in the past or identify your revenue growth.
When historical data that has been input into the system is studied using a mathematical model, the result can lead to suitable operational adjustments. Given the development of the Python framework in recent years, owing to its simplicity and capabilities, anyone can build a competitive predictive analytics model using Python.
This article will deep dive to cover the introductory look at predictive modeling and its process. Later, we’ll demonstrate the step-by-step process to build a successful predictive analytics model using the python framework and its corresponding results.
Predictive Analytics: History & Current Advances
When was the last time a piece of technology’s popularity grew exponentially, suddenly becoming a necessity for businesses and people? We see predictive analytics – tech that has been around for decades worth implementing into everyday life. To know why that has happened, let’s consider the reasons why:
- Provides exciting insights to predict your future decisions depending on the volume and type of input data.
- Provides easy-to-use models that help solve complex problems and uncover new opportunities for your organization.
- With more challenging economic conditions, it helps to be consistent in a growing competitive market.
The ability to use predictive algorithms is becoming more and more valuable for organizations of all sizes. It is particularly true for small businesses, which can use predictive programming to increase their competitive advantage by better understanding their customers and improving their sales.
Importance of Predictive Analytics in Fraud Detection
Predictive programming has become a considerable part of businesses in the last decade. Companies turn to predictive programming to identify issues and opportunities, predict customer behavior and trends, and make better decisions. Fraud detection is one of the everyday use cases that regularly suggests the importance of predictive modeling in machine learning.
Combining multiple data sets helps to spot anomalies and prevent criminal behavior. The ability to conduct real-time remote analysis can improve fraud detection scenarios and make security more effective.
Additional Read – Top 17 Real-Life Predictive Analytics Use Cases
Predictive Modeling: Process Breakdown
Here’s how predictive modeling works:
1. Collecting data
Data collection can take up a considerable amount of your time. However, the more data you have, the more accurate your predictions.
In the future, you’ll need to be working with data from multiple sources, so there needs to be a unitary approach to all that data. Hence, the data collection phase is crucial to make accurate predictions. Before doing that, ensure that you have the proper infrastructure in place and that your organization has the right team to get the job done.
Hiring Python developers can be a great solution if you lack the necessary resources or expertise to develop predictive models and implement data manipulation and analysis. Python is a popular data science and machine learning programming language due to its extensive libraries and frameworks like NumPy, pandas, scikit-learn, TensorFlow, and PyTorch.
It is observed that most data scientists spend 50% of their time collecting and exploring their data for the project. Doing this will help you identify and relate your data with your problem statement, eventually leading you to design more robust business solutions.
2. Analyzing data
One of the critical challenges for data scientists is dealing with the massive amounts of data they process. Identifying the best dataset for your model is essential for good performance. This is where data cleaning comes in.
Data cleaning involves removing redundant and duplicate data from our data sets, making them more usable and efficient.
Converting data requires some data manipulation and preparation, allowing you to uncover valuable insights and make critical business decisions. You will also need to be concerned with the cleaning and filter part. Sometimes, data is stored in an unstructured format — such as a CSV file or text — and you have to clean it up and put it into a structured layout to analyze it.
3. Feature engineering
Feature engineering is a machine learning technique using domain knowledge to pull out features from raw data. In other words, feature engineering transforms raw observations into desired features using statistical or machine learning methods.
A “feature,” as you may know, is any quantifiable input that may be utilized in a predictive model, such as the color of an object or the tone of someone’s voice. When feature engineering procedures are carried out effectively, the final dataset is optimal and contains all relevant aspects that impact the business challenge. These datasets generate the most accurate predictive modeling tasks and relevant insights.
4. Data modeling
You can use various predictive analytics models such as classification or clustering models. This is where predictive model building begins. In this step of predictive analysis, we employ several algorithms to develop prediction models based on the patterns seen.
Open-source programming languages like Python and R consist of countless libraries that can efficiently help you develop any form of machine learning model. It is also essential to reexamine the existing data and determine if it is the right kind for your predictive model.
For example, do you have the correct data in the first place? IT and marketing teams often have the necessary information, but they don’t know how best to frame it in a predictive model. Reframing existing data can change how an algorithm predicts outcomes.
5. Estimation of performance
In this step, we will check the efficiency of our model. Consider using the test dataset to determine the validity and accuracy of your prediction model. If the precision is good, you must repeat the feature engineering and data preprocessing steps until good results are achieved.

Building Predictive Analytics using Python: Step-by-Step Guide
1. Load the data
To start with python modeling, you must first deal with data collection and exploration. Therefore, the first step to building a predictive analytics model is importing the required libraries and exploring them for your project.
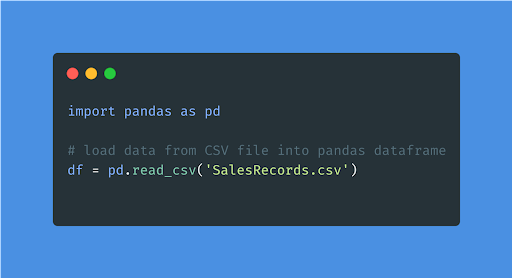
To analyze the data, one needs to load the data within the program, for which we can use one of the python libraries called “Pandas.”
The following code illustrates how you can load your data from a CSV file into the memory for performing the following steps.
2. Data pre-processing
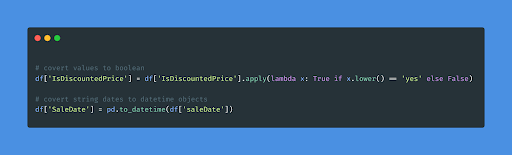
Now that you have your dataset, it’s time to look at the description and contents of the dataset using df.info() and df.head(). Moreover, as you noticed, the target variable is changed to (1/0) rather than (Yes/No), as shown in the below snippet.
3. Descriptive stats
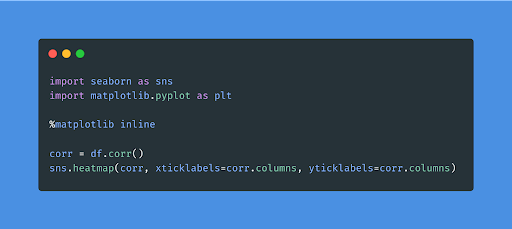
Descriptive statistics enables you to understand your python data model better and more meaningfully. As studied earlier, a better correlation between the data provides better accuracy in results. Hence, check for the correlation between various dataset variables using the below-given code.


4. Feature engineering
When dealing with any python modeling, feature engineering plays an essential role. A lousy feature will immediately impact your predictive model, regardless of the data or architecture.
It may be essential to build and train better features for machine learning to perform effectively on new tasks. Feature engineering provides the potential to generate new features to simplify and speed up data processing while simultaneously improving model performance. You may use tools like FeatureTools and TsFresh to make feature engineering easier and more efficient for your predictive model.
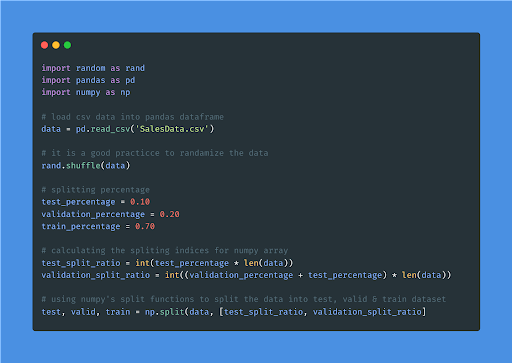
5. Dataset preparation
Before you go further, double-check that your data gathering is compatible with your predictive model. Once you’ve collected the data, examine and refine it until you find the required information for your python modeling.
The dataset preparation majorly focuses on dividing the datasets into three sub-datasets used to train and assess the model’s performance.
- Training Dataset
- Validation Dataset
- Test Dataset
6. Identify the variable
The choice of the variable for your project purely depends on which Python data model you use for your predictive analytics model. Moreover, various predictive algorithms are available to help you select features of your dataset and make your task easy and efficient.
Below are some of the steps to follow during the variable selection procedure of your dataset
- The weight of evidence is used to calculate the value of information.
- Using random forests to determine variable importance
- Elimination of recursive features
- Extra trees classifier with variable importance
- Best variables in chi-square testing
- Feature selection based on L1
7. Model development
You have to dissect your dataset into train and test data and try various new predictive algorithms to identify the best one. This fundamental but complicated process may require external assistance from a custom AI software development company. Moreover, doing this will help you evaluate the performance of the test dataset and make sure the model is stable. By this stage, 80% of your python modeling is done.

Let’s utilize the random forest predictive analytics framework to analyze the performance of our test data.
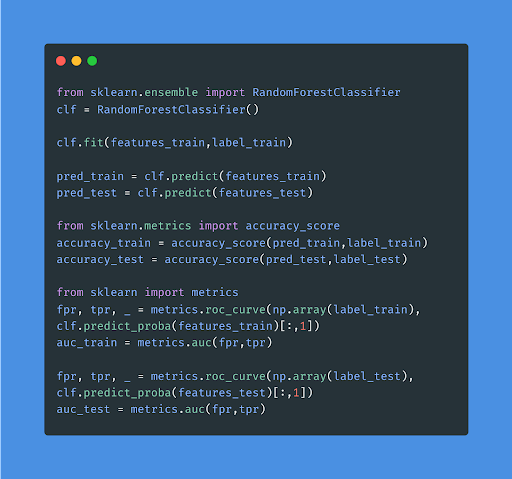
8. Hyperparameter tuning
You can also tweak the model’s hyperparameters to improve overall performance. For a better understanding, check out the snippet code below.
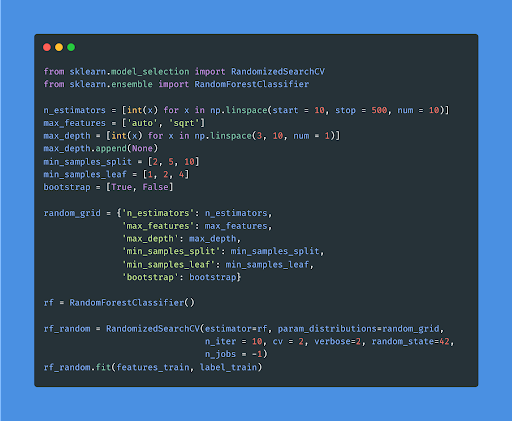
Testing with various predictive analytics models, the one that gives the best accuracy is selected as the final one.
9. Model evaluation
No, we are not done yet. While building a predictive analytics model, finalizing the model is not all to deal with. You also have to evaluate the model performance based on various metrics. Let’s go through some of these metrics in detail below:
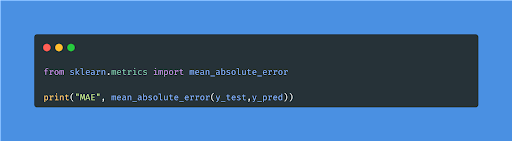
- Mean Absolute Error(MAE)
MAE is a straightforward metric that calculates the absolute difference between actual and predicted values. The degree of errors for predictions and observations is measured using the average absolute errors for the entire group.
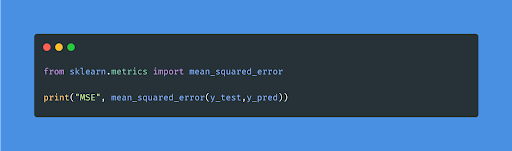
- Mean Squared Error(MSE)
MSE is a popular and straightforward statistic with a bit of variation in mean absolute error. The squared difference between the actual and anticipated values is calculated using mean squared error.
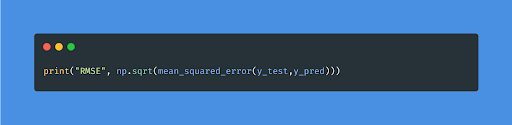
- Root Mean Squared Error(RMSE)
As the term, RMSE implies that it is a straightforward square root of mean squared error.
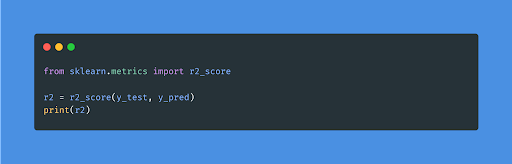
- R Squared (R2)
The R2 score, also called the coefficient of determination, is one of the performance evaluation measures for the regression-based machine learning model. Simply put, it measures how close the target data points are to the fitted line. As we have shown, MAE and MSE are context-dependent, but the R2 score is context neutral.
So, with the help of R squared, we have a baseline model to compare to a model that none of the other metrics give.
Conclusion
As competition grows, businesses seek an edge in delivering products and services to crowded marketplaces. Data-driven predictive models can assist these companies in resolving long-standing issues in unusual ways.
While there are numerous programming languages to pick from in today’s world, there are many reasons why Python has evolved as one of the top competitors. Python’s foundations are rooted in versatility since it can be used to construct applications ranging from Raspberry Pi to web servers and desktop applications.
This article discusses Python as a popular programming language and framework that can efficiently solve business-level problems. Out of the extensive collection of Python frameworks, Scikit-learn is one of the commonly used Python libraries, which contains many algorithms, including machine learning capabilities, to help your company leverage the power of automation and future possibilities.
The team of data scientists at Maruti Techlabs takes on the preliminary work of evaluating your business objectives and determining the relevant solutions to the posed problems. For instance, using the power of predictive analytics algorithms in machine learning, we developed a sales prediction tool for an auto parts manufacturer. The goal was to have a more accurate prediction of sales, and to date, our team is helping the company improve the tool and, thus, predict sales more accurately.
As a part of the agreement, we broke down the entire project into three stages, each consisting of a distinctive set of responsibilities. The first stage included a comprehensive understanding of our client’s business values and data points. Subsequently, our data scientists refined and organized the dataset to pull out patterns and insights as needed. In the final stage, our data engineers used the refined data and developed a predictive analytics machine learning model to accurately predict upcoming sales cycles. It helped our client prepare better for the upcoming trends in the market and, resultantly, outdo their competitors.
Here’s what the VP of Product had to say about working with us –
“The quality of their service is great. There hasn’t been a time when I’ve sent an email and they don’t respond. We expect the model to improve the accuracy of our predictions by 100%. Our predictions above a thousand pieces of parts are going to be 30% accurate, which is pretty decent for us. Everything under a thousand pieces will be 80% accurate.
Maruti Techlabs is attentive to customer service. Their communication is great even after the development. They always make sure that we’re happy with what we have. I’m sure that they’ll continue doing that based on the experience I’ve had with them in the past 8–9 months”.
With the help of our machine learning services, we conduct a thorough analysis of your business and deliver insights to help you identify market trends, predict user behavior, personalize your products and services, and make overall improved business decisions.
Get in touch with us today and uncover the hidden patterns in your business data.





















