
Click to learn more about author Andrea Ferretti.
Online learning is a branch of machine learning that has obtained a significant interest in recent years, thanks to its peculiarities that perfectly fit numerous kinds of tasks in today’s world. Let’s dive deeper into this topic.
What Exactly Is Online Learning?
In traditional machine learning, often called batch learning, the training data is first gathered in its entirety and then a chosen machine learning model is trained on said data: The resulting model is then deployed to make predictions on new unseen data.
This methodology, despite being wildly popular, presents several kinds of drawbacks and limitations when applied to some real-world tasks: Updating the model is very expensive, usually requiring a retraining of the model from scratch. Moreover, all the data has to be available before the training of the model, but in some cases that cannot happen since either the data set may be too large to be stored in its entirety, or the labels for the data points may be available at a later time than when the prediction is requested. [1, 2]
Think about the following use cases: online internet advertising, analysis of financial markets, product recommendations in e-commerce, sensors data analysis, movies, and music recommendations for entertainment.
They all present data that arrives sequentially in a streaming fashion at a high frequency. Ideally, we would want our model to continuously learn by taking the new incoming information (e.g., a user clicked on an ad, a stock price changed, a product was bought, a sensor transmitted a new reading) to immediately update itself and improve its performances.
As we stated, this is difficult to achieve with batch learning because we would have to add the new datapoint to our dataset and retrain the model completely on the changed dataset. Moreover, the training can take a lot of time (up to days, depending on the chosen model) and the dataset, especially with sensors data, may quickly become too large to be stored in its entirety; with the frequency at which new data arrives in today’s world, we cannot afford this.
Luckily, online learning allows us to avoid these problems: In the online learning paradigm, the model, optionally trained on some relevant data if available, is first deployed for inference; then, whenever a piece of new information arrives, the model is able to update itself quickly and efficiently by using only this new data. This enables the possibility of taking full advantage of the continuous feedback available in the aforementioned scenarios.
How Do We Fit Neural Networks and Deep Learning In?
Up to here, everything is all well and good, but things get a bit more complex once you actually try to use online learning.
For online learning to have good performances, both the model chosen and the way we’ll update it need to be sensitive enough so that even without a large amount of new feedback the model can meaningfully change the way it computes new predictions. On the other hand, it can’t be too sensitive, or the model would risk forgetting all the information contained in the previously seen data.
Because of this issue, neural networks and deep learning have not been associated with the online learning field, especially compared to classical machine learning, where they have affirmed themselves in the last decade.
Neural networks are a broad family of models that enjoy great representational power and adaptation capabilities for numerous applications. However, to achieve their full potential, neural networks need to have a considerable number of neurons, and the neurons have to be arranged in various layers stacked on top of each other forming deep networks. This gives the networks a rather complex and deep structure that needs lots of training data to function correctly, which is somewhat in tension with the aforementioned constraints of online learning.
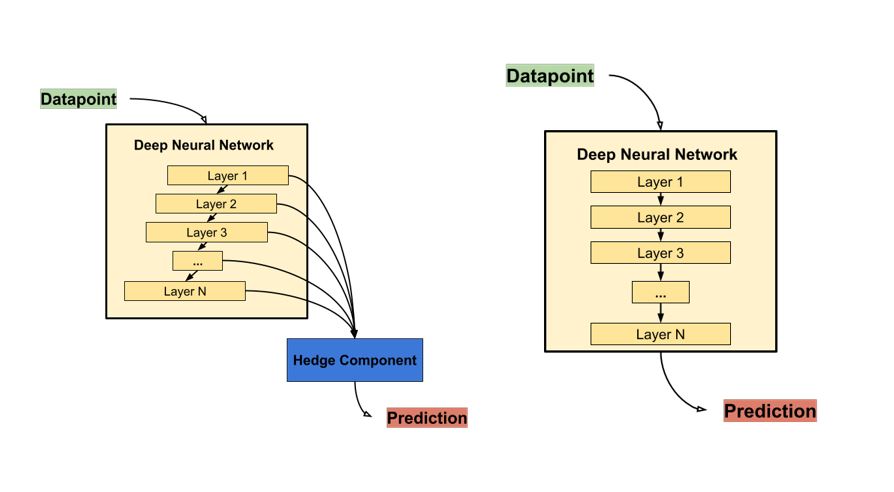
So how can we resolve this complexity vs. performance trade-off to successfully use neural networks in online learning? The idea is to combine a complex neural network and an additional component (called Hedge component) that is able to dynamically select for us the substructure of the original network that is better suited to make the prediction at any given time. [3]
This means we can leverage both the benefits of a deep network and a shallow one, automatically choosing whichever performs best based on the streaming data that arrives. The technique for training this kind of dynamic network needs to be customized as well, and it is called Hedge Backpropagation (HBP). Thanks to this method for updating the parameters of the Deep Neural Network effectively in an online learning setting, it’s possible even for a small amount of new information to meaningfully impact the model, but, at the same time, we retain the full power of a deep network should the data require it.
What About the System Architecture?
All right, so now we know what model we are going to use, but we still need to think about how we are going to implement the model, and also how to build a scalable and reliable distributed architecture that will allow us to serve it in a data streaming context.
First, we need to build a platform that is able to manage streams of incoming data with basic guarantees, such as the absence of data loss and data redundancy. Luckily, we don’t have to do everything ourselves, as there are a variety of stream processing engines that can be integrated into your platform to accomplish these tasks: Apache Kafka, Flink, and Spark, just to name a few.
For the model implementation we used TensorFlow 2, taking advantage of the Keras API, which makes the customization of both the network structure and the training algorithm pretty straightforward, and, at the same time, we retain the compatibility with the well-established TensorFlow ecosystem.
To handle the deployment we opted for Seldon-core, an open-source platform for rapidly deploying machine learning models, built on top of Kubernetes. Among the many facilities Seldon offers, we utilized a model deployer web-server that wraps our model and exposes REST endpoints for prediction and training. We also took advantage of the power of Kubernetes orchestration mechanisms, giving us the possibility to deploy multiple instances simultaneously, enabling horizontal scalability.
However, having multiple instances of the same model making predictions and receiving feedback forces us to analyze and solve the critical issues that always arise when working with distributed systems. So, as a final step, we designed and implemented a distributed updating mechanism that ensures that each instance of the deployed model will always use the latest version of the model to make predictions and that there will be no lost or spurious updates. To minimize the performance impact of these guarantees, we used Redis to store and retrieve quickly versioning information.
Finally, we obtained a scalable, distributed, platform-agnostic architecture where we can deploy our online learning model, serving requests for predictions and, when needed, training it on the newly available feedback.

References
[1] Online Learning: A Comprehensive Survey: https://arxiv.org/abs/1802.02871
[2] Online Machine Learning in Big Data Streams: https://arxiv.org/abs/1802.05872
[3] Online Deep Learning: Learning Deep Neural Networks on the Fly: https://arxiv.org/abs/1711.03705