
Click to learn more about author Aditi Raiter.
Are you in a work environment where streaming architecture is not yet implemented across all IT systems? Have you ever been in a situation when you had to represent the ETL team by being up late for L3 support only to find out that one of your team members had migrated a non-performant SQL to PROD? Are you an expert handling technical questions from a large build team leaving you no time to manage code designs/reviews for all projects? You are not alone – this article details out a strategy to overcome such concerns.
In a typical work environment, there are change control processes to request work from technical teams. A new change request enters the ETL queue, then requirements are gathered, quoted, and sent off to the build (development) team. If the build team has questions, they get help from seniors, or else they code common ETL best-practice tasks themselves. Most of them end up doing these tasks:
- Manually copy source DB data model on target environments. Add ETL identifiers to metadata
- Manually identify incremental change data capture strategy at table level
- Manually set up error handling mechanism on file creates/DB updates
- Manually set up audit logs
- Manually set up performance strategies by say bulk loads, parallel processes
- Manually set up recoverability/re-runnability mechanism by logging incremental data updates in target database based on source database time zone dates
- Set up mechanism to load history.
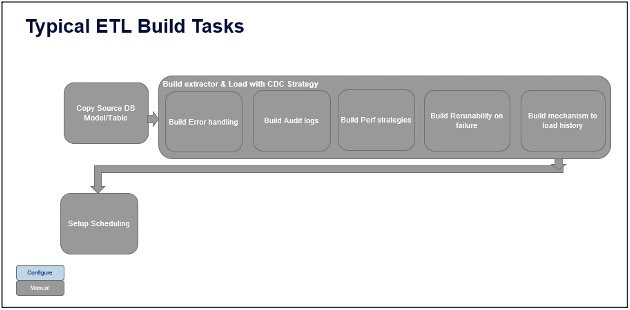
Common team challenges in the above typical ETL build process:
- No set ETL development standards on how to design performance, logging, commenting, naming, audit, error handling, etc. Team members usually look at older designs or code it per their understanding
- Inability to identify issues with the older ETL design functions
- Inability to allocate time for detailed code review sessions for all projects
- Inability to accommodate all UAT testing with IT maintainability test scenarios along with business test cases
- Quick-fix development approach in most situations
- Interest in loading huge historical data set without holistically considering implications for retrievals with table partitioning for all reporting use cases
These issues typically land in a complex ETL builds mesh:
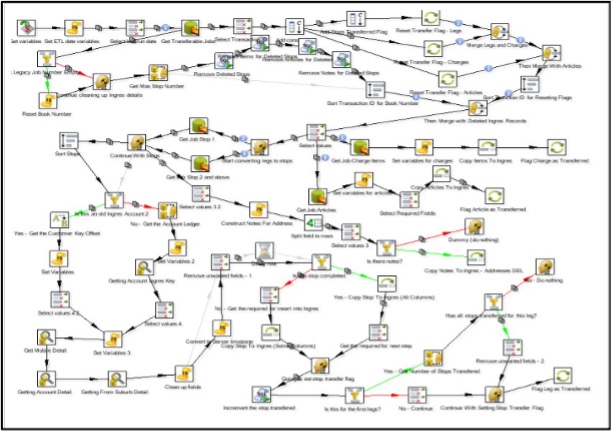
Although the code has ETL best practices implemented, many loads end up with the below discrepancies:
- Modularization scope does not remain consistent. Multiple functionalities end up being clubbed together in one module occasionally
- Multiple FTP server locations are set up per request to load and drop files to be picked up by application integration tools
- Missing comments on business rules
- Multiple log tables on a schema implemented for different projects
- Name variations in ETL build types:
1. Load to “Stage/Raw/Detail/Executor” tables from source tables
2. KPI builder jobs load to “Aggregators/KPI” tables
3. Loads from/to webservices follow varied table name conventions
4. Module naming conventions are also not consistent
You can imagine the effort spent to maintain these loads! It is not usable or maintainable.
To summarize, the main challenge is the ETL build team’s time is spent more as a technician rather than a mentor.These challenges can be overcome by improving maturity around ETL builds.
ETL Maturity Level
When it comes to platform maturity levels, most of the ETL platforms are managed. One of the key steps to a stable standardized platform is by implementing benchmarked functionality modules or build templates.

Recommended ETL Build Designs
The concept is to standardize all IT processes involving error handling, audit logging, performance strategies while loading into persistent stage tables, and re-runnability on failure log tables, and to build a mechanism to load history.
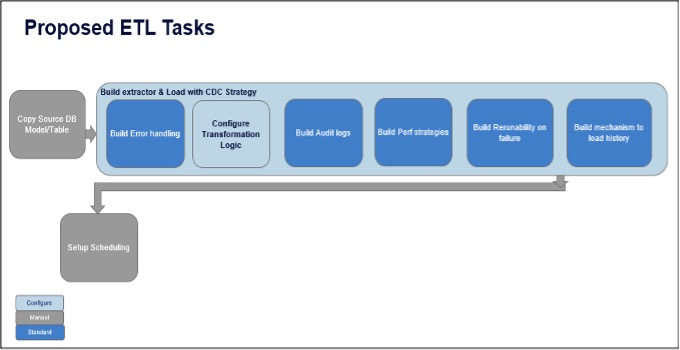
Possible ETL Build Approach
The idea of configuring and modularizing is not new, but segregating all enterprise ETL builds into standard functionality modules is unique.

We will talk about the proposed approach in the subsequent sections.
Build and Agree Atomic Template Types
Atomic template types can be built using metadata injection step in Pentaho Data Integrator (PDI) – community version (open-source ETL tool). Metadata injection is the dynamic ETL alternative to scaling robust applications in an agile environment.
It is used to build configurable transformation templates to get the outputs desired.
This mapping logic can look very similar on other tools. Below is an example on Pentaho Community open-source version.
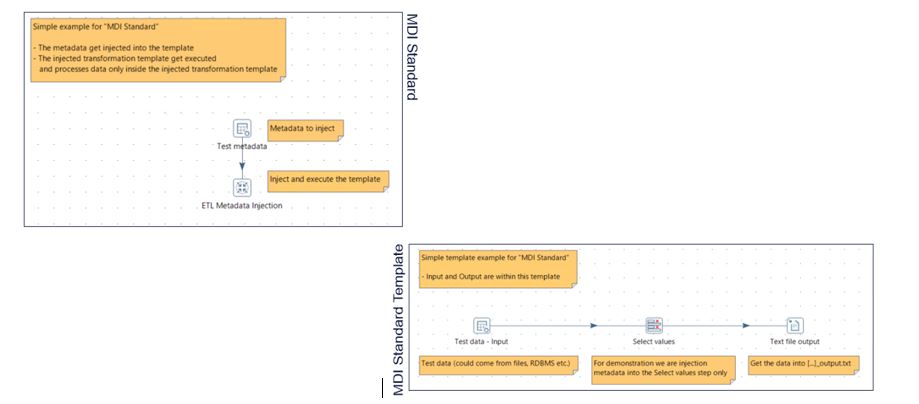
Build Standard Functionality Types with Atomic Templates
Standard functionality types are the common functionalities used to build ETL. Some examples include:
- Standard schema log update module
- Shared connection file read module
- Create and build FTP file module
- Source tables Extractor Module (Configuration Table for Source DB/Tables)
- Load to table based on CDC strategy module
- Bulk insert only load to PSA table module
- KPI aggregator (parameterized count) module
- Tables to Table De-normalizer module
Implement Configurable Master Job That Ties Standard Functionalities
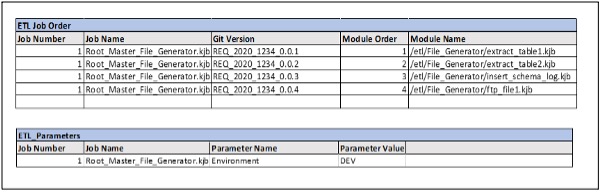
Chaining standard functionality modules in one job is not maintainable. Build a master job task that reads functionality modules from the configuration table. Build config tables for standard functionality modules (Jobs) and wrapper job parameters. Log the rows read and rows loaded for each functional module.
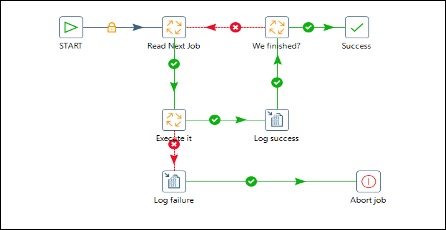
I would like acknowledge Veselin Davidov for a discussion on configurable PDI processes. Let’s take the idea to implement a large-scale enterprise use case for a global company.
Enterprise Use Case – PDI File Generator
Let’s take an example of an ETL use case where the requirement is to build an ETL load that generates a file. For such use cases, build a one-time file generator load that can accept configurable inputs indicating the desired file to be created.
This starts with designing a table for some of a configurable input as below:
- Source connection database type, name
- Sources select, from and where query
- Source File type, File name
- Transformation Rules
- Incremental Insert field ID/name
- Incremental Update field IDs/name
- Incremental Delete Log ID/name
- Target connection database type, name, table name
- Source File type, File name

The next step is to design and build functionality modules. Here are the main ones:
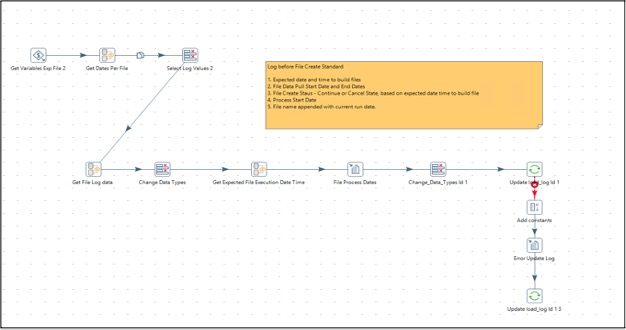
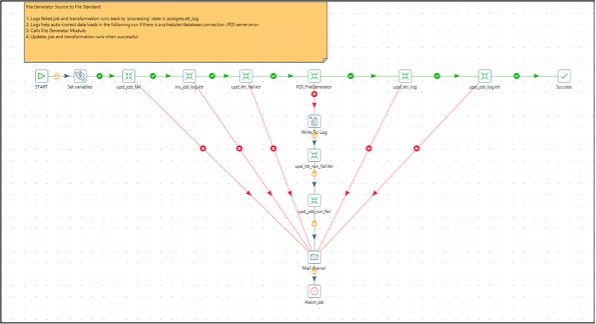
Log Before File Create Module
This module is used to create audit logs for the process before a file can be generated. The module scans through a list of files configured in filegenerator_table_to_file. It calculates the next expected date and time to build a configured file and logs a data pull start date. If the expected run time of the file is greater than the load run date, a file create status field is marked continue. If not, this is marked canceled. The name of file to be created is logged in a file name field.
Build and FTP Files
This module is used to build a file and FTP it to a configured location. The below sample also caters to an additional requirement to store the file in different locations along with FTP to an internal server.
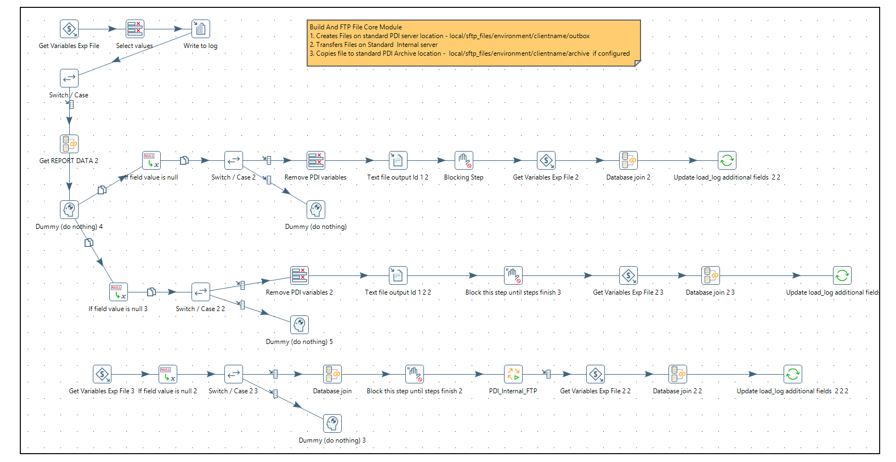
The Get Report Data step builds a file with a fully configurable code. The select statement is formed by reading parameters from the configuration table xml to connect to a database to build a file for the date range calculated. One option to use configurable connections is by utilizing a shared connection xml file. The load reads connection name as a parameter from the shared file.
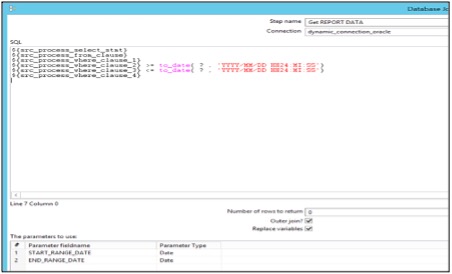
The above step can be replaced with a popular idea of using the metadata injection step as proposed by Diethard Steiner and a few others.
Wrapper Job
PDI wrappers generally have a re-runnability feature that can update logs before and after a process runs.
Configuration table for reading next core module:

The below configurable transformation reads core modules from the configuration table above.
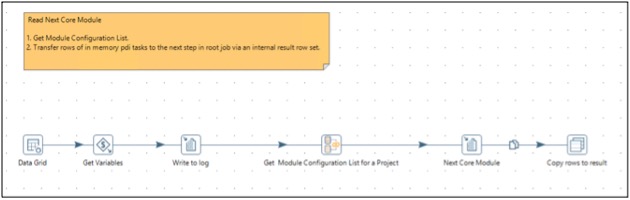
The below execute next module reads the module name from the previous transformation and executes it.
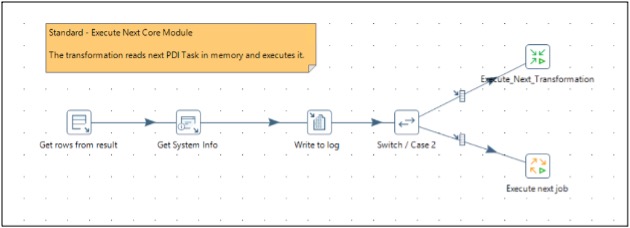
Once the load is built and reviewed, any new requirement to configure FTP file generation use cases is a matter of few steps. These are the following:
- Configure a file with an insert statement to the configuration table
- Create folders on FTP server to drop files
- Optionally create folders on additional servers to drop file copy
- Any new configuration will need to be tested to see if the select statement configured creates the files needed in the right location with proper log entries
Achievement Areas
These are some of the success areas with the process:
- Reduced time by about 90% for implementing similar new requests
- Reduced support documentation times by 90% for incorporating changes to standard modules
- Easily repeatable PDI functionality that can be configured to run for other use cases
- Easier logging by recording rows read, processed at standard functionality level
- Reduced PROD issues maintenance time by logging errors at the standard functionality levels
- Reduced Knowledge Transfer times by including comments for agreed business logic
- Recorded “how to configure” videos to scale trainer/originator
Closing Thoughts
Traditional ETL tools still have their place when it comes to batch daily KPI reporting or for real-time sensor data reporting catering near real-time use cases. Data analytics factories need not always be the Amazons and Googles of the world to demonstrate value generation. ETL build times can be drastically reduced using simple configurable designs for timely valuable insights.
To streamline the overall goal of improving predictability of ETL builds, a little change in mindset can do the trick:
- Start with a generic and scalable build thought process that can repurpose configurable standard functionalities for simple and cost effective designs
- Start with implementing readable code that reduces knowledge transition times
- Look for optimal designs to maintain reduced number of objects in source code repository
- Follow at least one time a stringent review process for core functionality modules
- Think efficiently to implement future performance scenarios